-
News Message
谷歌重磅开源RL智能
- by wittx 2020-04-13
智能体如何选择动作来实现其目标,这方面的研究已经取得了快速的进展,这在很大程度上归功于强化学习(RL)的使用。用于强化学习的无模型方法通过试错来学习预测成功的动作,这类方法使得 DeepMind 的 DQN 算法能够玩雅达利游戏,AlphaStar 在星际争霸 II 中击败世界冠军,但其需要大量的环境交互,由此限制了它们在真实世界场景中的应用。 与无模型 RL 方法不同,基于模型的 RL 方法需要额外地学习环境的简化模型。这类模型让智能体能够预测潜在动作序列的结果,在假想场景中进行训练,从而在新情境中做出明智的决策,最终减少实现目标所必需的试错次数。 在过去,学得精确的模型并利用它们学习成功的行为比较具有挑战性。但近来的一些研究,如谷歌提出的深度规划网络(Deep Planning Network,PlaNet),通过从图像中学习精确的模型推动了该领域的进展。但还需注意,基于模型的方法依然受到无效或计算代价高昂的规划机制掣肘,限制了它们解决复杂任务的能力。 今天,在最新的博客中,Google AI 与 DeepMind 联合推出了 Dreamer,这是一种从图像中学习模型并用它来学习远见性(long-sighted)行为的 RL 智能体。通过模型预测的反向传播,Dreamer 能够利用它学得的模型高效地展开行为学习。通过从原始图像中学习计算紧凑模型状态,Dreamer 仅使用一块 GPU 即可以高效地从预测到的并行序列中学习。 实验表明,在包含 20 个以原始图像作为输入的连续控制任务基准测试中,Dreamer 在性能、数据效率和计算时间三个方面均取得新的 SOTA 结果。Google AI 也已经开源了 Dreamer 的源代码。 论文地址:https://arxiv.org/pdf/1912.01603.pdf GitHub 博客地址:https://dreamrl.github.io GitHub 项目地址:https://github.com/google-research/dreamer
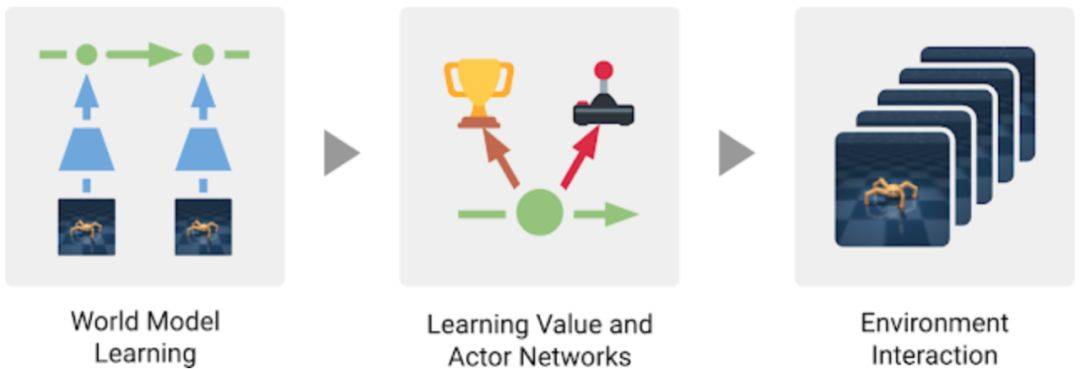
Dreamer 的工作原理 Dreamer 由基于模型强化学习方法中的三个典型流程组成: 学习真实环境的模型
从模型的预测中学习动作策略
在真实环境中执行习得的策略,并收集环境产生的新数据
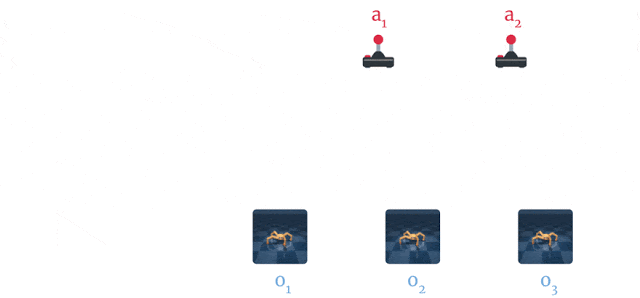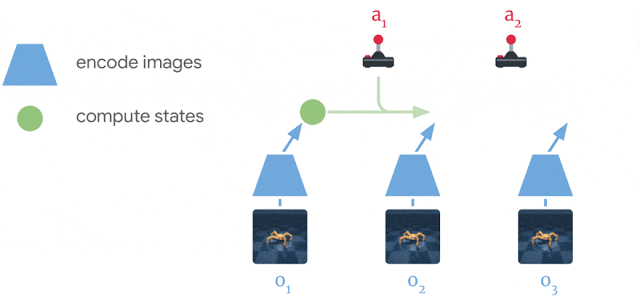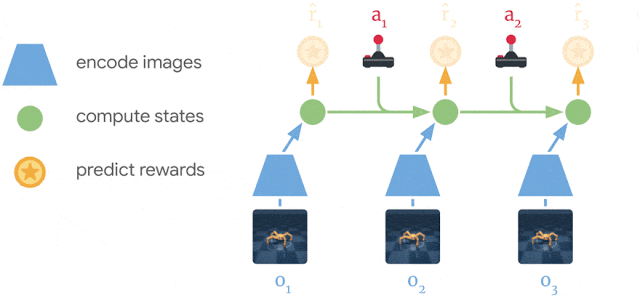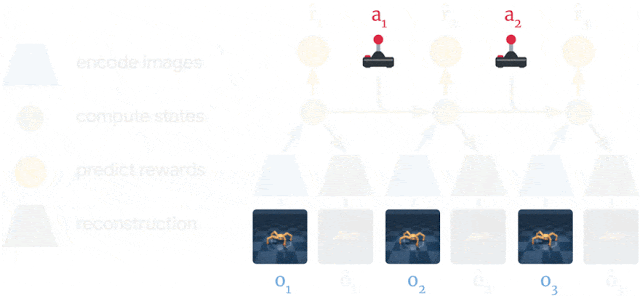
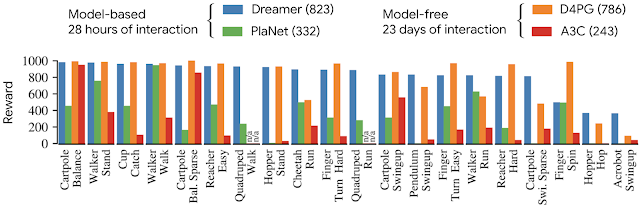
为学习到良好的策略,Dreamer 使用一个估值网络来考虑规划范围之外的奖赏值,同时使用一个策略网络来高效地计算相应动作。以上三个流程(可各自并行执行)不断循环迭代,直到智能体实现其在环境中的目标。 Dreamer 的三个工作流程。模型从过去收集到的数据中进行学习。智能体从模型的预测中学习出一个预测未来奖赏的估值网络和一个选择动作的策略网络。策略网络被用来与真实环境进行交互。 模型学习 Dreamer 使用了 PlaNet 中的模型,该模型基于一系列从图像输入计算而来的紧凑模型状态预测之后的状态,而不是直接使用当前获得的图像预测下一时刻的图像。这个模型能够学会自动地产生诸如物体类型、物体位置以及物体与周围环境相互作用这类具有象征性概念的模型状态,这些象征性概念有助于其预测未来状态。从智能体数据集中采样一系列过去的图像、动作以及奖赏值数据,Dreamer 的模型学习过程如下图所示: Dreamer 从过去的经验中学习出一个环境的模型。Dreamer 使用过去的图像 (o_1–o_3) 和动作 (a_1–a_2),计算出一系列紧凑的模型状态(图中以绿色圆圈表示),并使用这些状态重构出图像 (ô_1–ô_3) 以及预测奖赏值 (r̂_1–r̂_3)。 使用 PlaNet 模型的优势之一在于其极大地提升了计算效率,它通过紧凑的模型状态对未来状态进行预测而不是直接使用图像来预测。这使得该模型能够仅使用一个 GPU 就可以并行地预测上千个样本序列。该方法同时也有助于模型的泛化,能够实现准确的长序列视频预测。为了探寻该模型的运行过程,研究者通过将紧凑模型状态解码为图像来可视化模型预测序列。下图显示了 DeepMind Control Suite 与 DeepMind Lab 环境中某一任务的预测情况: 使用紧凑模型状态能够实现在复杂环境中的长序列预测。以上两个序列为智能体之前没有遇到过的情形。给定 5 个连续的图像作为输入,模型能够重建并预测出在这之后 50 步的图像。 高效的策略学习 以往基于模型的智能体通常使用以下两种方式选择动作,一是通过多个模型预测来规划,二是用模型取代模拟器以重用现有的无模型方法。这两种方式都需要很大的计算量,并且无法充分利用学得的模型。此外,即使强大的模型也会受限于其能够精确预测的步长,这使得以往很多基于模型的智能体存在短视的问题。Dreamer 通过对其模型预测的反向传播,学得对应估值网络与策略网络,进而克服了这些限制。 Dreamer 通过预测状态序列将奖赏值梯度反向传播(在无模型方法中是无法实现的),以此能够高效地习得策略网络来预测成功的动作。这能够让 Dreamer 了解到其动作小幅度更改是如何对未来预测奖赏值产生影响的,使得它能够朝着将奖赏值最大化的方向改进其策略网络。为了在预测范围外考虑奖赏,估值网络为每个模型状态的未来累积奖赏值做出估计。然后将这些奖赏值与估值反向传播以改进策略网络,最终选择改进后的动作: Dreamer 从模型预测的状态中学习远见性行为,它首先学习每个状态的长期价值(v̂_2–v̂_3),接着通过状态序列将动作反向传播至策略网络,进而预测那些生成高奖励和价值的动作。 Dreamer 与 PlaNet 存在着几方面的不同。对于环境中的特定情境,PlaNet 在诸多不同的动作序列预测中搜索最佳动作。Dreamer 则不同,它通过去耦化规划和行动规避了这一计算花销大的搜索过程。只要在预测序列上训练了它的策略网络,Dreamer 在无需额外搜索的情况下即可计算与环境进行交互的动作。此外,Dreamer 使用估值函数来考虑规划周期外的奖励,并利用反向传播进行高效规划。 算法效果 研究者使用了 20 个不同任务的标准基线对模型进行了测评。这些任务有连续动作和图像作为输入。任务包括平衡、捕捉目标以及各种模拟机器人的移动。 这些任务被设计用来给 RL 智能体施加各种挑战,包括预测碰撞的困难性、稀疏的奖励、混乱的动量、小而关联的目标、高自由度以及 3D 条件等。 Dreamer 学习去解决 20 个任务,其中 5 个如上图所示。可视化显示,64x64 图像作为智能体从环境中的输入。 研究者将 Dreamer 和 PlaNet、A3C、D4PG 等模型进行了对比。PlaNet 是目前最好的基于模型的智能体,A3C 则是最好的无模型智能体,D4PG 则结合了一些无模型强化学习的优势。基于模型的智能体学习了 500 万帧图像,对应了 28 小时的模拟。无模型智能体学习地更慢,需要 1 亿帧图像,对应了 23 天的模拟。 以下为模型性能的对比,可以看到 Dreamer 比 D4PG 性能更好,而且少了 20 倍的环境交互。 在 20 个任务上,从性能表现、数据利用效率和计算时间三个方面,Dreamer 都比 D4PG 和 PlaNet 方法优秀。 除了在连续控制任务上的实验外,研究者还发现了当它被用于离散行为时,Dreamer 具有良好的泛化能力。他们采用了雅达利游戏和 DeepMind Lab 级别来进行评价。 这需要智能体具有互动性和远见性的行为、空间感知能力、以及对于视觉上最不同的场景的理解能力。结果显示,Dreamer 能够学习这些具有挑战性的任务。 Dreamer 在雅达利游戏上有着成功的表现。这种测评任务有着以下特征:需要离散动作和有视觉差异大的场景,包括对于多个目标的 3D 环境等。 结论 谷歌的这项研究表明,从模型预测的序列中学习行为可以解决图像输入中具有挑战性的视觉控制任务,性能也优于先前的无模型方法。此外,Dreamer 也表明,通过紧凑模型状态的预测序列来反向传播值梯度,进而学习行为,这种方式非常成功且具有鲁棒性,解决了各种连续和离散控制任务。 研究者认为,Dreamer 为进一步突破强化学习的限制打下了坚实基础,包括实现更好的表示学习、具有不确定性估计的定向探索以及时间抽象和多任务学习等。 文末附上 Dreamer 之前版本 PlaNet 的项目及论文链接: https://github.com/google-research/planet https://arxiv.org/pdf/1811.04551.pdf 谷歌博客原文链接:http://ai.googleblog.com/2020/03/introducing-dreamer-scalable.html
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=270

Best Last Month

Information industry by wittx

Information industry by wittx
Information industry by wittx
Information industry by wittx
Electronic electrician by wittx
Information industry by wittx
Electronic electrician by wittx
Information industry by wittx
Information industry by show

Information industry by wittx