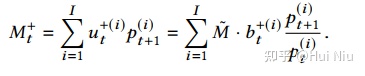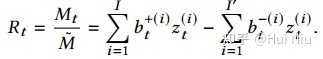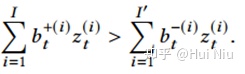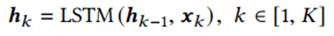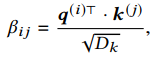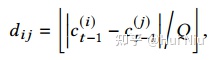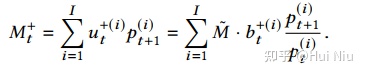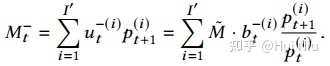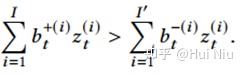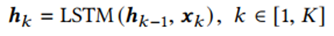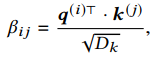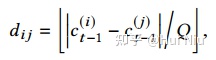-
News Message
AlphaStock
- by wittx 2022-11-23
AlphaStock: A Buying-Winners-and-Selling-Losers Investment Strategy using Interpretable Deep Reinforcement Attention Networks
1. 金融术语

- 持有期 :投资最小时间单位。
- 序列投资:投资序列是一系列持有期的序列。
- 资产价格: , 这里 是股票i在t时刻的价格。
- 多仓 :
- 多仓是先在 时刻买入股票后面 时刻卖掉平仓的操作
- 利润是 , 是购买股票i的量。
- 空仓:
- 空仓是先在 时刻借入股票卖掉后面 时刻买入还回股票的操作
- 利润是 , 是借入股票i的量。
- 投资组合:
- 如果有 只股票,一个投资组合定义为 , 这里 是股票i的资金占比,
- 零-投资组合:
- 资产组合的资金记为 , 多仓的,而空仓
- 对于有J个资产组合的投资组合来说,如果,那么它就是零-投资组合。
2. BWSL策略
这一节介绍问题建模和设定。
本文使用的策略是买入winner售出loser策略(buy-winners-and-sell-losers (BWSL) ),这里的winner和loser指的是股票集合中预测可能涨价更多的和涨价少甚至跌得多的股票。
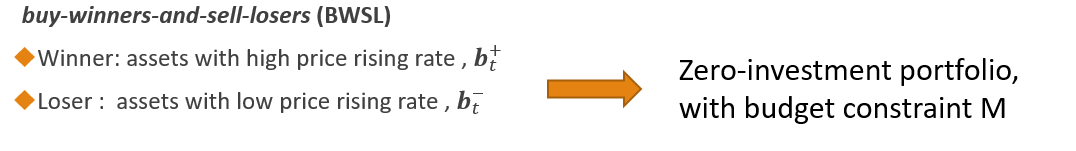
具体执行过程是:
1. 在时间t, 借入“loser”股票并且卖掉他们:
在时刻t,给定预算 ,我们借“loser”并卖掉(开空仓)。我们能借的股票i的量是:
其中 是股票i在空仓组合 中的比例。
2. 在时间t, 买入“winner”:
(开多仓)能够买入股票i的量是
3.在第t个持有期结束时,卖出多仓组合:
我们能得到的金额是所有股票在t+ 1时以新价格出售股票的收益,
4. 在第t个持有期结束时,买回空仓组合:
我们花在买空头股票上的金额是
5. 回报率
总的收益是 ,将价格涨幅记作 ,最后回报率为
目标
如果我们想要 ,那么需要
这意味着,股票价格的绝对涨跌不是主要关注点;相反,股票之间的相对价格关系要重要得多。
优化目标
夏普比率

3. AlphaStock模型
这一节介绍具体算法。
AlphaStock一共包含了3个部分:简单来说就是
- 股票特征提取(LSTM-HA)
- 股票间相对关系抽取(CAAN),
- 根据上涨得分产生投资组合(portfolio generator)
三部分;比较一目了然:
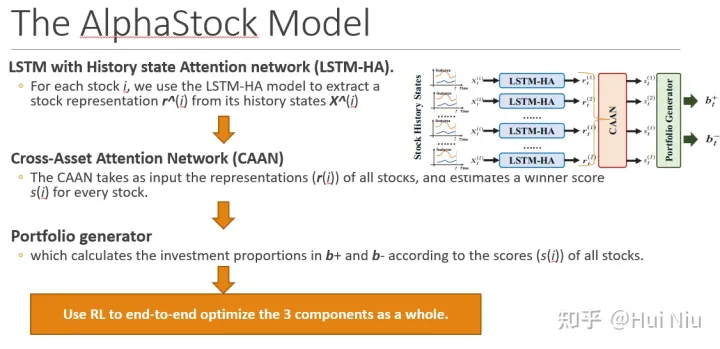
LSTM-HA、CAAN、portfolio generator 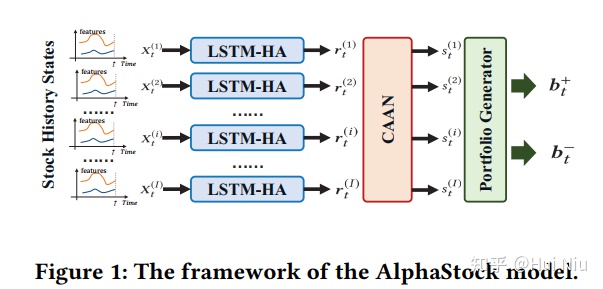
具体来说就是上图从左到右的过程:
- 每只股票的原始特征经过LSTM-HA(历史注意力网络)产生股票特征表示 ;
- 然后用CAAN(股票间的注意力网络)将不同的股票特征进行比较整合,产生一个上涨分数,称作winner score ;
- 这样就可以根据得分,筛选出用来做多和做空的股票,再用softmax等方式产生资金分配;
- 最后,有了资产组合后,就可以计算获得的利润,那么就可以使用RL优化了。
现在我们按照图片上从左到右(白蓝红绿)的顺序介绍具体的算法:
(1)原始特征
用了技术面和基本面两种因子,具体来说就是下面这7个。


(2)股票特征提取
我们将时间t的最后K个历史持有时段,即从时间t - K到时间t的时间段,称为t的回顾窗口。
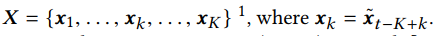
我们的模型使用长短期记忆(LSTM)网络递归地将X编码成向量为
其中 为LSTM在第k步编码的隐藏状态,将最后一步的作为股票的表示。它包含X中元素之间的顺序依赖关系。
这一部分的创新是:使用了history state attention,用所有的中间隐藏状态 来增强 。按照标准的注意力机制,增强后的表示记为r,计算为

属于时间关系的一种特征提取。
(3)股票相对价格关系预测
The Basic CAAN Model
CAAN模型采用自注意机制,给定股票的表示 ,我们为股票i计算一个查询向量 ,一个关键向量 和一个值向量
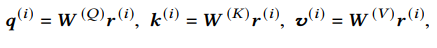
股票 j 与股票 i 的相互关系建模为:使用股票i的 来查询股票j的 ,即(其中Dk是缩放参数):
然后,我们将归一化的相互关系 作为权重,将其他股票的 值相加,得到整合的分数:
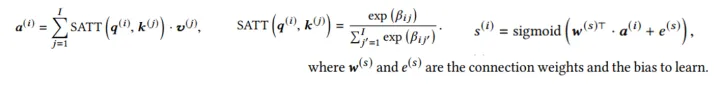
Incorporating price rising rank prior.
这部分是使用历史的价格上涨率排名先验来对上面的权重β做一个改进版。
我们用 表示股票 i 在上一次持有期间(从t - 1到t)的价格上升率的排名。
我们用股票在坐标上的相对位置作为股票相互关系的先验知识。在坐标轴上计算它们的离散相对距离
其中Q为预设量化系数。
我们使用查找矩阵 来表示每个离散值 。以 为索引,对应的列向量 是相对距离 的嵌入向量。

得到新的β后仍是上面的操作。(根据最后的实验结果,加了这个先验有一点点提升)
(4)投资组合
我们首先将股票按照赢家分数降序排序,得到每个股票i的序号o(i),选前G个用来开多仓,后G个用来开空仓,使用softmax分配仓位:
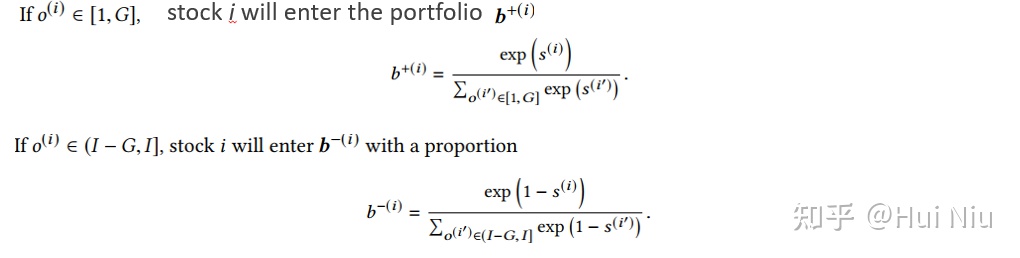
最后记作 维度是I,前G维和 相同,后G维和 相同,其余维度是0.
(5)使用RL优化网络
轨迹
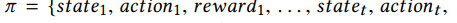
动作是一个I维二进制向量,当agent投资股票i时,元素动作(i) t = 1,否则为0。
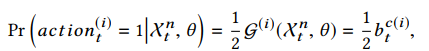
设定好reward
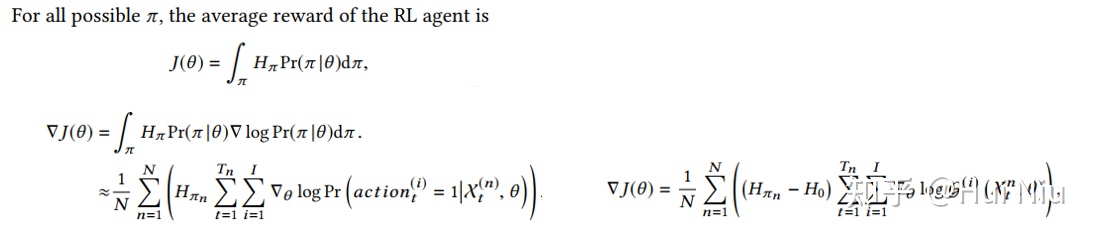
这样就可以用RL优化了。
4. 实验结果
对比的方法和评估标准如下:

做了一些ablation,AS-NC指的是没有使用股票间的CAAN结构;AS-NP是没有使用排名先验来改进CAAN。
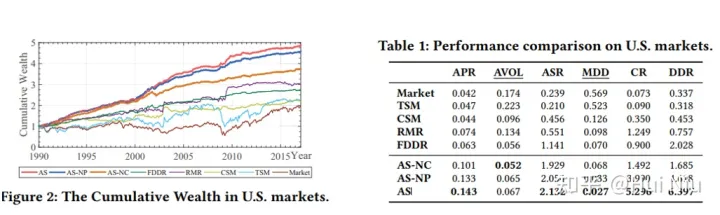
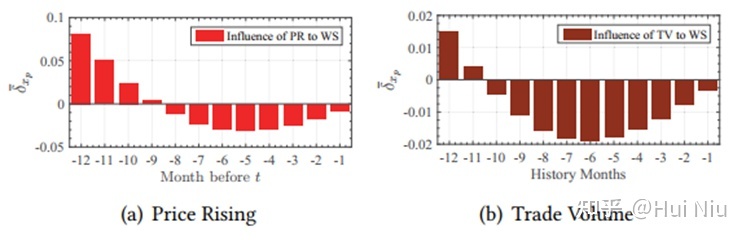
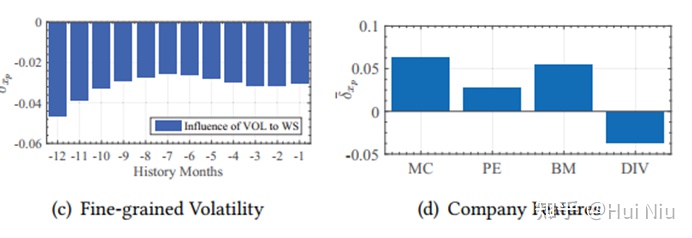
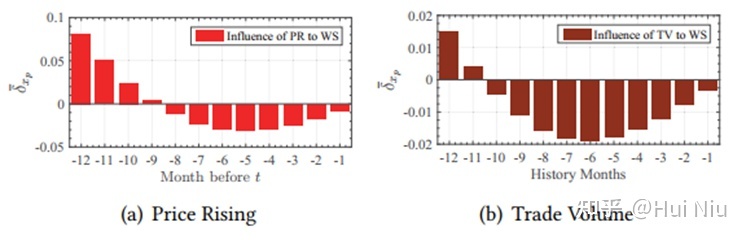
还画出了不同时间长度的因子对于“winner score”的影响,是个比较有趣的实验发现:可以看到9-12个月前涨价现在涨价的影响是正面的,而过去8个月的涨价被认为是不利因素。交易量也有相似的效应。
1. 金融术语

- 持有期 :投资最小时间单位。
- 序列投资:投资序列是一系列持有期的序列。
- 资产价格: , 这里 是股票i在t时刻的价格。
- 多仓 :
- 多仓是先在 时刻买入股票后面 时刻卖掉平仓的操作
- 利润是 , 是购买股票i的量。
- 空仓:
- 空仓是先在 时刻借入股票卖掉后面 时刻买入还回股票的操作
- 利润是 , 是借入股票i的量。
- 投资组合:
- 如果有 只股票,一个投资组合定义为 , 这里 是股票i的资金占比,
- 零-投资组合:
- 资产组合的资金记为 , 多仓的,而空仓
- 对于有J个资产组合的投资组合来说,如果,那么它就是零-投资组合。
2. BWSL策略
这一节介绍问题建模和设定。
本文使用的策略是买入winner售出loser策略(buy-winners-and-sell-losers (BWSL) ),这里的winner和loser指的是股票集合中预测可能涨价更多的和涨价少甚至跌得多的股票。
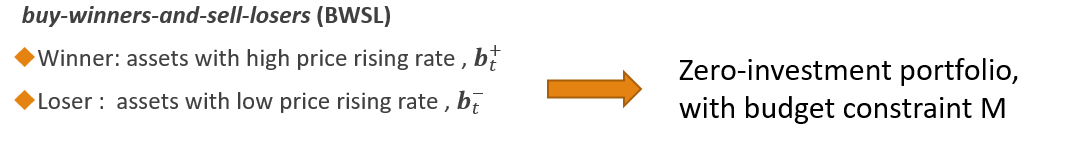
具体执行过程是:
1. 在时间t, 借入“loser”股票并且卖掉他们:
在时刻t,给定预算 ,我们借“loser”并卖掉(开空仓)。我们能借的股票i的量是:
其中 是股票i在空仓组合 中的比例。
2. 在时间t, 买入“winner”:
(开多仓)能够买入股票i的量是
3.在第t个持有期结束时,卖出多仓组合:
我们能得到的金额是所有股票在t+ 1时以新价格出售股票的收益,
4. 在第t个持有期结束时,买回空仓组合:
我们花在买空头股票上的金额是
5. 回报率
总的收益是 ,将价格涨幅记作 ,最后回报率为
目标
如果我们想要 ,那么需要
这意味着,股票价格的绝对涨跌不是主要关注点;相反,股票之间的相对价格关系要重要得多。
优化目标
夏普比率

3. AlphaStock模型
这一节介绍具体算法。
AlphaStock一共包含了3个部分:简单来说就是
- 股票特征提取(LSTM-HA)
- 股票间相对关系抽取(CAAN),
- 根据上涨得分产生投资组合(portfolio generator)
三部分;比较一目了然:
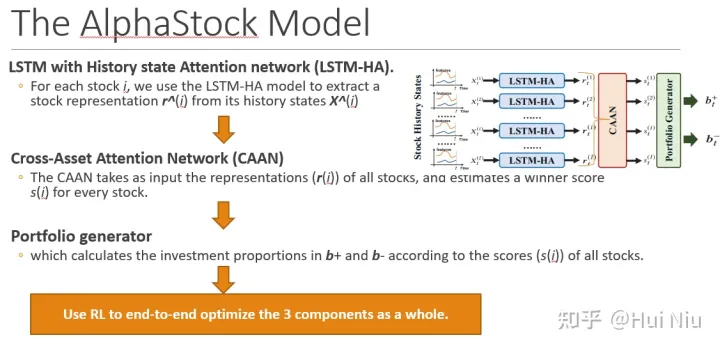
LSTM-HA、CAAN、portfolio generator 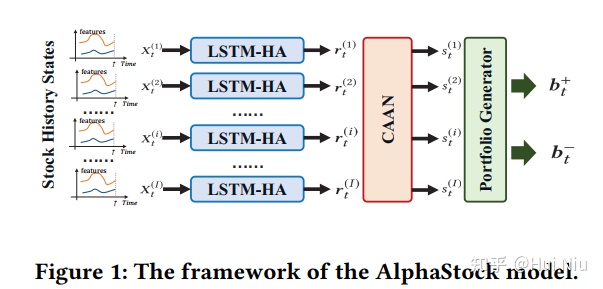
具体来说就是上图从左到右的过程:
- 每只股票的原始特征经过LSTM-HA(历史注意力网络)产生股票特征表示 ;
- 然后用CAAN(股票间的注意力网络)将不同的股票特征进行比较整合,产生一个上涨分数,称作winner score ;
- 这样就可以根据得分,筛选出用来做多和做空的股票,再用softmax等方式产生资金分配;
- 最后,有了资产组合后,就可以计算获得的利润,那么就可以使用RL优化了。
现在我们按照图片上从左到右(白蓝红绿)的顺序介绍具体的算法:
(1)原始特征
用了技术面和基本面两种因子,具体来说就是下面这7个。


(2)股票特征提取
我们将时间t的最后K个历史持有时段,即从时间t - K到时间t的时间段,称为t的回顾窗口。
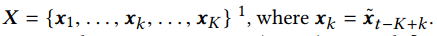
我们的模型使用长短期记忆(LSTM)网络递归地将X编码成向量为
其中 为LSTM在第k步编码的隐藏状态,将最后一步的作为股票的表示。它包含X中元素之间的顺序依赖关系。
这一部分的创新是:使用了history state attention,用所有的中间隐藏状态 来增强 。按照标准的注意力机制,增强后的表示记为r,计算为

属于时间关系的一种特征提取。
(3)股票相对价格关系预测
The Basic CAAN Model
CAAN模型采用自注意机制,给定股票的表示 ,我们为股票i计算一个查询向量 ,一个关键向量 和一个值向量
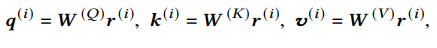
股票 j 与股票 i 的相互关系建模为:使用股票i的 来查询股票j的 ,即(其中Dk是缩放参数):
然后,我们将归一化的相互关系 作为权重,将其他股票的 值相加,得到整合的分数:

Incorporating price rising rank prior.
这部分是使用历史的价格上涨率排名先验来对上面的权重β做一个改进版。
我们用 表示股票 i 在上一次持有期间(从t - 1到t)的价格上升率的排名。
我们用股票在坐标上的相对位置作为股票相互关系的先验知识。在坐标轴上计算它们的离散相对距离
其中Q为预设量化系数。
我们使用查找矩阵 来表示每个离散值 。以 为索引,对应的列向量 是相对距离 的嵌入向量。

得到新的β后仍是上面的操作。(根据最后的实验结果,加了这个先验有一点点提升)
(4)投资组合
我们首先将股票按照赢家分数降序排序,得到每个股票i的序号o(i),选前G个用来开多仓,后G个用来开空仓,使用softmax分配仓位:
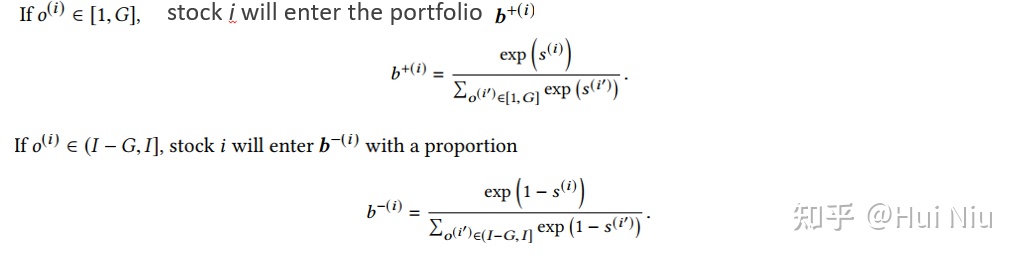
最后记作 维度是I,前G维和 相同,后G维和 相同,其余维度是0.
(5)使用RL优化网络
轨迹
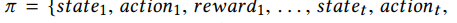
动作是一个I维二进制向量,当agent投资股票i时,元素动作(i) t = 1,否则为0。
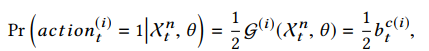
设定好reward
这样就可以用RL优化了。
4. 实验结果
对比的方法和评估标准如下:

做了一些ablation,AS-NC指的是没有使用股票间的CAAN结构;AS-NP是没有使用排名先验来改进CAAN。
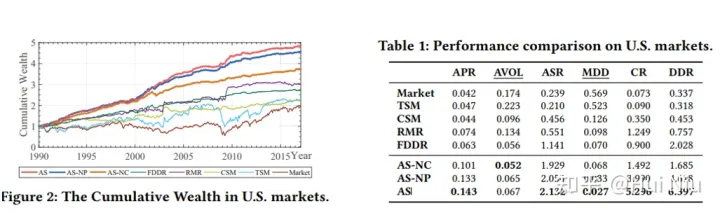
还画出了不同时间长度的因子对于“winner score”的影响,是个比较有趣的实验发现:可以看到9-12个月前涨价现在涨价的影响是正面的,而过去8个月的涨价被认为是不利因素。交易量也有相似的效应。
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1043

Best Last Month
Electronic electrician by wittx
Electronic electrician by wittx
Information industry by wittx
Information industry by wittx
.jpg)
Medical science by wittx
Information industry by wittx
Information industry by wittx
Information industry by wittxRapid inverse design of metamaterials based on prescribed mechanical behavior through machine learni

Information industry by wittx
Information industry by wittx