
-
News Message
Temporal Difference Learning
- by wittx 2020-09-04
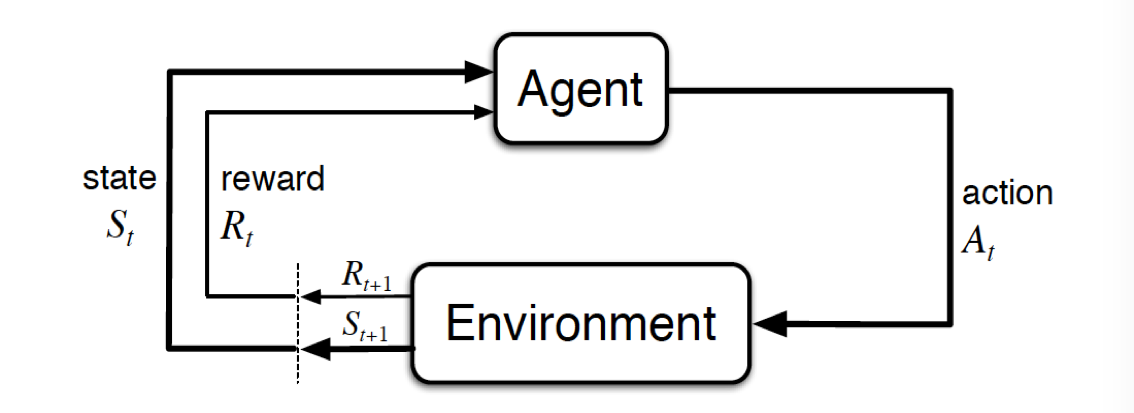
时序差分学习(Temporal-Difference Learning)结合了动态规划和蒙特卡洛方法,是强化学习的核心思想。
蒙特卡洛的方法是模拟(或者经历)一段序列,在序列结束后,根据序列上各个状态的价值,来估计状态价值。
时序差分学习是模拟(或者经历)一段序列,每行动一步(或者几步),根据新状态的价值,然后估计执行前的状态价值。
可以认为蒙特卡洛的方法是最大步数的时序差分学习。
DP,MC和TD的区别
DP:已知转移概率是精确算出来的,用的是当前的估计值。
MC:用多个episode的近似
TD:和用的都是当前的估计值
本章介绍的是时序差分学习的单步学习方法。多步学习方法在下一章介绍。主要方法包括:
策略状态价值的时序差分学习方法(单步\多步)
策略行动价值的on-policy时序差分学习方法: Sarsa(单步\多步)
策略行动价值的off-policy时序差分学习方法: Q-learning(单步)
Double Q-learning(单步)
策略行动价值的off-policy时序差分学习方法(带importance sampling): Sarsa(多步)
策略行动价值的off-policy时序差分学习方法(不带importance sampling): Tree Backup Algorithm(多步)
策略行动价值的off-policy时序差分学习方法: (多步)
策略状态价值的时序差分学习方法(单步\多步)
单步时序差分学习方法
该算法就通过当前状态的估计与未来估计之间差值来更新状态价值函数的。即
相比DP,TD不需要知道;相比MC,TD不需要等到序列结束才更新状态值函数,另外MC趋向于拟合样本值,会表现出类似过拟合的性质,TD在估值前会对潜在的Markov过程建模,然后基于该模型估值。例如下面的例子:
多步时序差分学习方法
单步的报酬为:
其中在这里是在时刻t对的估计,而表示对后面时刻的估计,即,由此可以得到n步的报酬:
则更新公式为:
n-step TD就是利用值函数来不断估计不可知的报酬,则整体框架如下:
策略行动价值的on-policy(即同策略)时序差分学习方法: Sarsa(单步\多步)
单步:
Sarsa在选取动作和更新动作状态值函数时都时利用加探索的形式()
多步:
类似n-step TD,报酬的形式只是从状态值函数改为了动作状态值函数:
则更新形式为:
整体框架为:
策略行动价值的off-policy时序差分学习方法: Q-learning(单步)
Q-learning 算法可进行off-policy学习。
Q-learning在更新动作状态值函数时只有利用,没有探索,更适用于完全贪婪的动作挑选。
Q-learning使用了max,会引起一个最大化偏差(Maximization Bias)问题。可以用Double Q-Learning来解决。
例如图中从A出发,向右可以直接到达终点,而向B运动,报酬均值为-0.1,则有可能存在大于0的报酬,这样会使得算法采取向B运动的结果,期望获得大于0的报酬,而这不是最佳策略。
Double Q-learning
挑选动作的策略,既可来自于Q1和Q2的组合,例如求和或者均值,又可只来自于Q1或Q2。
策略行动价值的off-policy时序差分学习方法(带importance sampling): Sarsa(多步)
考虑到重要样本,把带入到Sarsa算法中,形成一个off-policy的方法。
- 重要样本比率(importance sampling ratio)
策略行动价值的off-policy时序差分学习方法(不带importance sampling): Tree Backup Algorithm(多步)
Tree Backup Algorithm的思想是每步都求行动价值的期望值.
更新公式与n-step Sarsa相同:
则整体程序框架为:
策略行动价值的off-policy时序差分学习方法: (多步)
结合了Sarsa(importance sampling), Expected Sarsa, Tree Backup算法,并考虑了重要样本。
当σ=1时,使用了重要样本的Sarsa算法。
当σ=0时,使用了Tree Backup的行动期望值算法。
---------------------
作者:Mr丶Caleb
来源:CSDN
原文:https://blog.csdn.net/qq_30159351/article/details/72896220
版权声明:本文为博主原创文章,转载请附上博文链接!
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=175

Best Last Month
Information industry by wittx
Information industry by wittx
Information industry by wittx
Mechanical electromechanical by wittx
Information industry by wittx
Information industry by wittx

Information industry by wittx
Information industry by wittx
Information industry by wittx

Information industry by wittx
