News Message
Aplha Evolve 实现自我进化,code GPU内核算法性能提升21%!
- by wittx 2025-07-06
用户发布的文档
1、什么是Aplha Evolve?
Alpha Evolve是谷歌旗下的研究机构Deepmind发布的一个研究成果,是一个科学和算法领域的代码智能体。Alpha Evolve基于Deepmind过去的研究成果为一身的处理复杂代码和数学问题的智能体。所以我们需要预习一下Deepmind过去推出的明星项目(AlphaGo、Alpha Zero、Alpha Fold、Alpha Dev、Fun search),以及Alpha Evolve是如何对前代研究的继承。
2、Deepmind前代研究回顾
2017年AlphaGo:超越人类的围棋程序
2016年3月,一个名为 AlphaGo Lee 的程序,击败了围棋世界冠军李世石。这就像是一个科幻电影的情节变成了现实,一个人工智能程序在人类智慧的巅峰领域之一取得了胜利。这件事立刻引起了巨大的轰动。许多人认为围棋是人类直觉、创造力和复杂策略的体现,机器很难真正理解和掌握。
但是AlphaGo的胜利打破了这种观念,证明了人工智能可以在这种复杂且需要深刻理解的领域超过了人类水平。突破了过往AI的局限。传统的围棋程序,即使使用蒙特卡洛树搜索(MCTS),也往往结合了大量人类专家的知识和策略。而最初的 AlphaGo虽然也使用了 MCTS,但它的核心是深度神经网络。通过学习人类专家的棋谱来预测走法,并通过与自己对弈的强化学习来提升能力。这种结合了深度学习和强化学习的方法,是其成功的关键。
然而,真正的科学界轰动,是在此之后。DeepMind发布的AlphaGo Zero。AlphaGo Zero 采取了一种更为激进的方法:它完全抛弃了人类棋谱、指导或任何知识,除了最基本的围棋规则。它仅仅通过与自己对弈进行强化学习,从“空白石板”(tabula rasa)开始学习围棋。AlphaGo Zero 从完全随机的下法开始,只靠自我博弈,在短短几天内就达到了超人类水平。它甚至以100:0的成绩击败了之前的 AlphaGo。这强有力地证明了,纯粹的强化学习方法,即使没有人类经验的输入,也能够独立地发现和掌握复杂领域的知识,甚至超越人类的最佳水平。 在自我对弈过程中,AlphaGo Zero 不仅重新发现了许多过去就存在的围棋经典定式,还发现了非标准和全新的策略,这些策略人类都未曾发现。这表明 AI 不仅仅是模仿人类,甚至可以超越人类。
AlphaGo Zero 的成功表明,“空白石板”式的强化学习方法是可行的。这为构建更通用的、能够解决多种复杂问题的 AI 算法奠定了基础。这直接促成了后来 AlphaZero 项目的出现。
2018年AlphaZero:通用强化学习解决复杂决策
在 AlphaGo Zero 的基础上,被应用于国际象棋和日本将棋等多种游戏,同样在短时间内达到了超人类水平。AlphaZero 沿用了 AlphaGo Zero 的核心方法—白板强化学习(tabula rasa reinforcement learning)。它从完全随机的走法开始,通过与自己进行大量博弈来学习。在这个过程中,它使用深度神经网络来预测每一步可能的走法以及当前局面的胜率。这些预测完全是根据它在自我博弈中获得的经验来学习和调整的。它不依赖复杂的、人工设计的搜索技术,同样使用蒙特卡洛树搜索(MCTS)方法,由神经网络的预测来指导搜索方向。
AlphaZero 证明了,通用强化学习算法,足以在多个复杂的抽象任务中达到并超越人类顶尖水平。这极大地推动了对构建通用人工智能(AGI)算法的研究兴趣。AlphaZero 的成功,促使研究人员思考如何将这种“从零开始”的强化学习和基于深度学习的评估/策略网络应用到游戏之外的其他更广泛的复杂问题中。
2020年Alpha Fold:预测蛋白质三维结构
生命体里有无数种蛋白质,它们是构建身体、执行各种功能的关键分子。蛋白质就像是由一串氨基酸组成的“链条”,但它们工作的时候不是链条的状态,而是会折叠成一个非常复杂、精妙的三维结构。正是这个独特的三维结构决定了蛋白质的功能。
科学家们很久以前就认识到,蛋白质的氨基酸序列里包含了它如何折叠的所有信息。但要仅仅根据这个一维的氨基酸序列,来准确预测出它在三维空间里会折叠成什么样子,是生物学领域的一个长期巨大挑战。这个空间非常大,可能的折叠方式非常多,要找到那个正确的、稳定的结构,难如登天。
几十年来,科学家们为此付出了巨大的努力,发展了各种预测方法,但精度总是有限。
每年都有一个国际性质的比赛,叫做 CASP(Critical Assessment of protein Structure Prediction),好比蛋白质结构预测领域的“世界杯”或“奥林匹克”是行业的黄金标准评估,大家拿出自己最厉害的算法来比拼谁的预测最接近真实的蛋白质结构。
然后在 2020 年的 CASP14 大赛上,DeepMind 开发的 AlphaFold的表现轰动了整个科学界。
AlphaFold 预测的蛋白质结构远远比当时任何其他方法都要准确得多。它预测的结构,主链原子的中位误差只有 0.96 埃,而排名第二的方法,误差是 2.8 埃。一个碳原子的直径大约是 1.4 埃。AlphaFold 的预测精度已经达到了接近原子尺度的水平,这已经非常接近实验测量所能达到的精度了。它不仅主链准确,侧链原子(决定蛋白质很多细节功能的关键部分)的预测也表现出色,甚至能预测非常长的蛋白质结构。
为什么 AlphaFold 能做到这一点?
它不是依赖于大量的规则库或者简单的模板匹配,而是核心使用了深度神经网络。这个网络学习了蛋白质结构预测背后的进化、物理和几何约束。它吃进去的“原材料”是蛋白质的氨基酸序列,以及与这个序列相关的其他蛋白质序列(叫做多序列比对,MSAs)。神经网络通过学习海量的已知蛋白质结构数据来理解序列和结构之间的复杂关系。
而且AlphaFold 的预测过程非常快速。以前科学家可能需要几个月甚至几年才能通过实验解析一个蛋白质结构,而 AlphaFold 在 GPU 上只需要几分钟到几小时,就能给出一个预测结果。它还能给出预测结果的置信度评分,让科学家知道预测的哪些部分是高度可靠的。
它的背后结合了领域知识(进化、物理约束)和强大的深度学习/强化学习技术(和 AlphaZero 的精神是相通的)。
2022年Alpha Dev:发现最优排序算法
我们每天用的所有软件、应用,背后都依赖于一些非常基础、核心的算法,比如给一堆数据排序,或者处理数据结构。这些算法就像是软件世界的“地基”和“砖瓦”。其中一些最基础的算法,比如排序算法,每天在全球范围内被执行数万亿次。
这些基础算法的效率至关重要。即使是微小的提升,乘以数万亿次的执行量,累积起来都能节省巨大的计算资源。科学家和工程师们几十年来一直在努力优化这些算法,特别是它们最终编译成的低级汇编代码(assembly),因为它直接对应着 CPU 执行的指令。但要在如此底层、如此优化的代码上找到进一步提升的空间是非常困难的。
DeepMind 看中了这个难题,他们开发了一个新的 AI 系统,叫做 AlphaDev。它的目标就是从零开始,去发现比现有最好的人类设计的算法更高效的版本。
AlphaDev 是怎么做到的呢?它不像传统的编程方式,而是参考AlphaGo的精神,把“寻找更好算法”这件事变成了一个单人游戏。这个游戏的环境就是低级汇编指令的世界。AlphaDev 就是那个玩家,它学习如何在这个游戏里“玩得好”,而“玩得好”的定义就是找到一个正确且高效(低延迟)的算法序列。
AlphaDev 使用深度神经网络来指导一个 MCTS 过程。这个网络吃进去的是当前已经构建的汇编代码状态,输出是下一步可能添加哪些汇编指令的概率以及对最终算法效率的预测,通过自我不断尝试构建和改进算法来学习。
AlphaDev的结果非常惊人。
AlphaDev 发现了一些小型排序算法的汇编实现,这些实现在某些情况下比现有人类专家优化的版本更短或更快。还发现了一些新的算法结构和指令序列,这些新发现能够减少指令数量,提升效率。发现了一种完全不同于人类benchmark的变长排序(variable sort)算法的组织方式,这种新方法带来了显著的长度和延迟优势。这些由 AlphaDev 发现的算法已经被集成到了被广泛使用的 LLVM 标准 C++ 库中。这意味着全球数百万开发者和应用都在使用 AlphaDev 发现的更优算法。
除了排序,AlphaDev 还展现了通用性,成功优化了其他领域的算法,比如谷歌内部常用的数据格式 Protocol Buffer 的反序列化函数(VarInt),找到了一个更短、快了大约三倍的实现。它甚至被应用于优化数据中心调度、LLM 训练、TPU 电路设计等工程问题,带来了实际的效率提升。
总的来说,AlphaDev 的故事展示了人工智能,特别是基于强化学习和树搜索的 AI 系统,不仅能在游戏世界里超越人类,更能深入到计算机科学的基础领域,发现并改进那些最核心、最底层的算法。这不仅为软件和硬件的效率带来了实实在在的提升,也为 AI 在更广泛的科学和工程领域的算法发现开辟了新的道路。
2023年Fun search:找出难发现但易验证的解/方法。
可以把 FunSearch 想象成一个拥有超级创意助手和极其严格评审团的特殊研究工作室。
1.创意助手(LLM - 大型语言模型):它的任务就是提出各种可能的程序想法,但有时候会写出貌似正确但有问题的代码(就像有时候 LLM 产生幻觉一样)。
2.严格评审团(Evaluator - 评估器):为了避免LLM的幻觉,工作室有一个严格的评审团,也就是评估器。当创意助手写出一个程序后,评审团会实际运行这个程序,然后用一个事先设定好的“评估函数”给它的输出打分。只有通过了评审团严格测试、表现良好的程序,才会被认可。FunSearch 特别适合那些问题本身很难直接解决,但很容易验证或评估一个候选解的质量的问题7...。
3.程序数据库(Programs database):那些通过评审团测试的优秀程序,会被收入到一个数据库里。这个数据库里的程序就是 FunSearch 迄今为止发现的“最佳实践”集合。为了保持数据库的“多样性”,不让想法都局限在少数几种上,这个数据库被巧妙地分成了几个“岛屿”。每个岛屿自己发展,但岛屿之间会定期交流,表现不好的岛屿会被“重置”,并学习表现最好的岛屿里的优秀程序。
4.学习和演化(Evolutionary process):数据库不是死的,而是一个不断演化的过程。创意助手会从数据库里挑选一些得分最高的程序,然后基于这些优秀程序去构思和生成新的、希望更优秀的程序版本。这些新程序再提交给评审团测试,如果表现好,就加入数据库,甚至取代旧的程序。这个过程就像生物进化一样,优胜劣汰,只不过这里进化的是程序。
5.程序骨架(Skeleton):有时候,为了让创意助手更有效率,人类专家会提供一个基本的程序框架或“骨架”。这个骨架包含了解决问题的一些已知步骤或通用结构,而让创意助手去填写最关键、最需要创新的那部分逻辑。这就像给助手一个带有大部分结构的蓝图,只让它设计最核心的部件。
通过这个“创意助手 + 严格评审团 + 演化数据库”的模式,FunSearch 取得了令人瞩目的成果:
•在纯数学领域做出新发现:它被应用于一个叫做“盖集问题”(cap set problem)的著名数学难题。这是一个研究具有特定性质的集合大小的问题,几十年来人类专家一直在努力寻找更大的盖集。FunSearch 成功地发现了比之前人类所知更大的盖集构造,甚至改进了相关的数学下限。
•代码启发人类洞察:更神奇的是,科学家们分析了 FunSearch 生成的程序代码,竟然从中发现了一些新的数学规律或“对称性”。这些人类从 AI 代码中获得的洞察,又被用来指导和改进后续的 FunSearch 搜索,从而发现了更好的结果。这是一种非常有趣的人机协作模式。
•优化实际应用算法:除了纯数学,FunSearch 还被用于优化实际的计算机算法,比如在线装箱问题(online bin packing)。这在物流、调度等领域非常常见,目标是用最少的箱子装下陆续到来的物品。FunSearch 发现了一些新的装箱启发式算法,这些算法在测试中表现优于人类长期使用的经典算法。这些发现有潜力被用于优化像谷歌数据中心那样的计算任务调度 。
与 AlphaDev 专注于低层汇编代码的优化不同,FunSearch 更像是去发现和改进更高层次的算法逻辑或数学构造方法。它不是直接给出最终结果,而是提供一个程序,这个程序本身就是一种知识。由于搜索的是程序而不是庞大的结果列表,它能处理规模更大的问题,并且生成的程序往往更易于理解和解释。
总而言之,FunSearch 的故事表明,通过巧妙地结合大型语言模型的创造力、自动化评估的严谨性以及进化算法的探索能力,人工智能可以成为科学家和工程师在发现新知识、发明新算法方面的强大工具,甚至能提供启发人类思考的新视角。
3、2025年Alpha Evolve:
你可以把 AlphaEvolve 理解成一个超级进化的 FunSearch,它变得更强大、更灵活,能解决更大、更复杂的问题,甚至能深入到 Google 自己最核心的基础设施去优化代码。
AlphaEvolve 是一个进化的代码智能体 (evolutionary coding agent)。它的核心思想是,在很多科学研究和工程问题中,发现一个更好的算法或者数学构造比评估一个解的好坏要难很多。那么,AlphaEvolve 就把目标放在了发现这些“最优解”的程序上。
AlphaEvolve 就像一个拥有一支精英团队和一高效而且能自动化评估的研究实验室。
1.LLM 团队 (LLMs ensemble):这是一群非常擅长理解、生成和修改代码的 LLM。它们是实验室里的“创意大脑”,负责根据现有的“最佳实践”提出各种改进程序的想法或直接生成新的程序代码。AlphaEvolve 使用了先进的 LLM,比如 Gemini 2.0 Flash 和 Gemini 2.0 Pro 的组合,Flash 模型负责快速生成大量候选,而 Pro 模型则提供更高质量、更有突破性的想法。这使得 AlphaEvolve 比之前的FunSearch更强大。
2.程序数据库 (Program database):和FunSearch一样,它也有一个不断增长的数据库,里面存储着 AlphaEvolve 迄今为止发现的、并且经过严格评估的、表现优秀的程序。这个数据库借鉴了FunSearch的思想,比如分成了不同的“岛屿”,来维持程序的多样性,避免所有想法都集中在少数几种上。
3.严格评估器 (Evaluators pool):每当 LLM 团队提出了一个新程序或修改建议,这个严格的评审团就会实际运行代码,并根据用户定义的自动化评估标准(一个函数 h)给它打分。这个评估过程是高度自动化的,并且可以并行执行,甚至可以持续评估数小时。评估器还可以设计成一个“级联”系统,先用简单的测试快速筛掉不好的程序,再用更难的测试来评估有潜力的程序。这种机制是 AlphaEvolve 的核心优势,因为它直接用代码执行结果来验证和评估,大大减少了 LLM 幻觉问题,AlphaEvolve 甚至可以同时优化多个评估指标。
4.进化过程 (Evolutionary process):AlphaEvolve 的核心驱动力是一个进化算法。它会从程序数据库中选择得分高的程序作为“灵感”.。然后,LLM 团队会根据这些优秀程序(通常通过生成代码修改块,即 diffs)来创建新的“子代”程序。这些新程序再交给评估器打分,表现好的就进入数据库,取代表现差的。这个过程就像程序的优胜劣汰和迭代改进。用户可以提供一个初始程序的“骨架”,并标记出需要由 AlphaEvolve 进化的代码块.
4、Alpha Evolve的成果
纯数学发现:它被应用于解决著名的数学难题,成功发现了比人类之前已知更好的构造。例如,它改进了 Erdős 的“最小重叠问题”的上限,以及在 11 维空间中“亲吻数问题”的下限,找到了能同时接触中心球体的 593 个球体的配置,超过了之前的记录 592 个。它还在多种几何和填充问题中找到了新的最佳边界。
矩阵乘法算法改进:在查找更快矩阵乘法的张量分解算法方面,AlphaEvolve 改进了 14 种矩阵乘法算法的已知上界。最引人注目的是,它为 4x4 复数矩阵的乘法找到了一种使用 48 次标量乘法的算法,这是 56 年来首次在这一特定设置下超越 Strassen 算法。
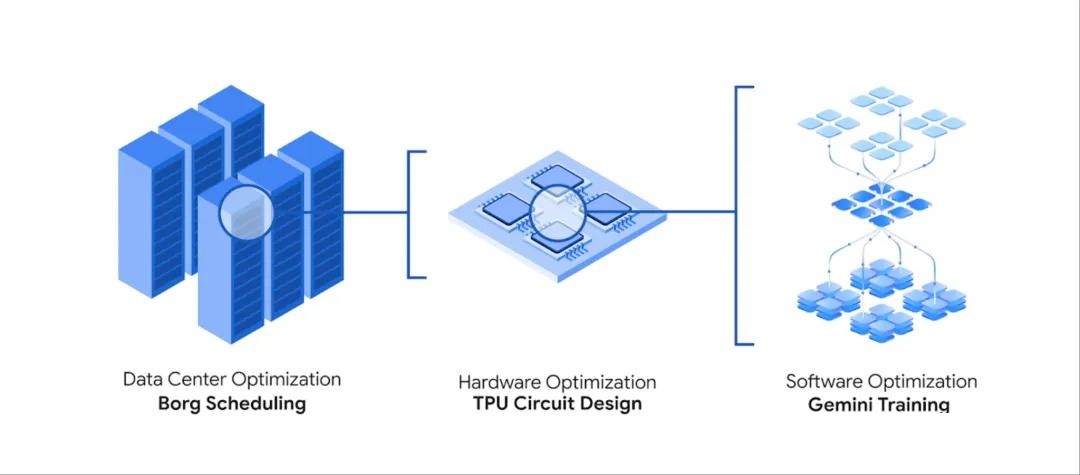
优化 Google 核心基础设施:AlphaEvolve 被用于优化 Google 计算栈的关键组件。
数据中心调度:它发现了一个比现有生产环境使用的更高效的调度启发式函数,部署后平均恢复了 Google 舰队 0.7% 的计算资源。而且,与强化学习方法相比,AlphaEvolve 生成的代码更易于解释、调试和部署。
TPU 电路设计:TPU 是 Google 自家研发的、专用于 AI 计算的超级加速芯片,它让 Google 能够更快、更强大地运行和开发 AI 模型。AlphaEvolve 在 TPU 算术电路的 Verilog 实现中发现了功能的等价简化,移除了不必要的比特,这有助于减少面积和功耗。这是 Gemini 通过 AlphaEvolve 对 TPU 电路设计的第一个直接贡献。
LLM 训练优化:它优化了用于训练 Gemini 等 LLM 的矩阵乘法内核 (kernels),使得内核平均加速 23%,Gemini 的整体训练时间减少了 1%。这还将优化时间从几个月缩短到几天。这标志着 Gemini 通过 AlphaEvolve 优化了自身的训练过程。
优化编译器生成代码:它甚至能直接优化像 FlashAttention 这样的高性能计算库经编译器 (XLA) 生成的中间表示 (IR) 代码。在一个重要的 Transformer 模型配置上,它使得 FlashAttention 内核加速 32%,前/后处理部分加速 15%4。
启发人类洞察:通过分析 AlphaEvolve 发现的程序代码,研究人员能够获得新的数学洞察,有时甚至反过来指导进一步的搜索
5、面临的挑战
1、AlphaEvolve 能够处理的问题的前提是必须能够设计一个函数 h 来自动化地评估生成的解决方案(比如算法或构造)的好坏,并给出得分。这意味着对于那些需要大量人工实验、主观判断或难以用明确指标自动衡量的任务,AlphaEvolve 目前是无法处理的。
2、评估过程的设计和效率:尽管 AlphaEvolve 可以进行长时间和并行的评估,但如何高效地设置评估器,特别是对于需要数小时并行计算的任务,以及如何利用评估级联(Evaluation Cascade)来快速过滤掉不好的程序,这些都需要精心的设计和实现。如果评估不够高效,会显著减慢进化过程的速度。
3、程序数据库的设计:维护一个不断增长的程序数据库,既要存储优秀的解决方案,又要保持足够的多样性以鼓励探索,避免陷入局部最优,这是进化算法固有的挑战,AlphaEvolve 的数据库设计(借鉴了 MAP-elites 和岛屿模型)就是为了应对这一挑战。
4、依赖底层 LLM 的能力:虽然 AlphaEvolve 通过自动化评估显著地规避了大型语言模型的“幻觉”(hallucinations),因为它会实际运行和验证 LLM 生成的代码,但它的创意生成(Creative generation)步骤仍然依赖于底层 LLM 的能力。消融研究表明,使用更强大的 LLM(如 Gemini 2.0 Pro)结合更快的 LLM(如 Gemini 2.0 Flash),能够带来更好的性能。因此,底层 LLM 的创造力、理解复杂代码的能力以及生成正确修改(diffs)的能力仍然是影响 AlphaEvolve 效果的关键因素。
5、自我改进的效率:尽管 AlphaEvolve 已经展示了优化自身基础设施和 LLM 训练的能力,但目前这些改进带来的收益是“适度的”,而且反馈循环需要“数月”的时间。提高这种自我改进的速度和规模是一个未来的发展方向。
参考资料:
1、【AlphaGo】Mastering the Game of Go without Human Knowledge
2、【AlphaZero】Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
3、【AlphaFold】Highly accurate protein structure prediction with AlphaFold
4、【AlphaDev】Faster sorting algorithms discovered using deep reinforcement learning
5、【FunSearch】Mathematical discoveries from program search with large language models
6、【AlphaEvolve】AlphaEvolve: A coding agent for scientific and algorithmic discovery
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1471


Best Last Month





.jpg)

.jpg)