近来,几种长上下文语言模型陆续问世,包括 GPT-4(上下文长度为 32k)、MosaicML 的 MPT(上下文长度为 65k)Anthropic 的 Claude(上下文长度为 100k)。长文档查询和故事写作等新兴用例已经表明扩展语言模型上下文窗口是非常必要的。
然而,扩大 Transformer 的上下文长度是一个挑战,因为其核心的注意力层在时间复杂度和空间复杂度与输入序列长度的平方成正比。
一年前,来自斯坦福大学、纽约州立大学布法罗分校的研究者共同提出一种快速、内存高效的注意力算法 ——FlashAttention。该算法无需任何近似即可加速注意力并减少内存占用。现在,已经有许多机构和研究实验室采用 FlashAttention 来加速训练和推理。
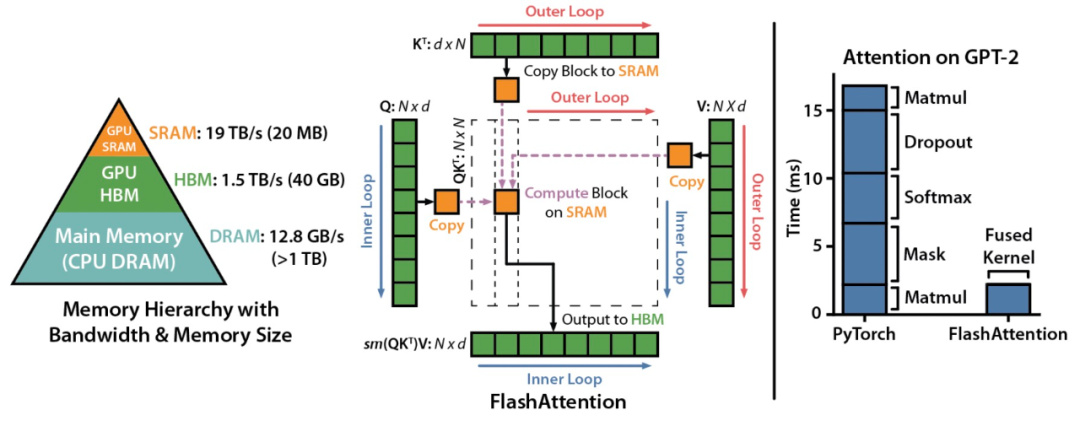
FlashAttention 示意图。
尽管 FlashAttention 的速度已经是优化基线的 2-4 倍,但它仍然有相当大的改进空间。FlashAttention 仍然不如优化过的矩阵乘法 (GEMM) 运算快,仅达到理论最大 FLOPs/s 的 25-40%。
现在,研究团队宣布推出 FlashAttention-2。FlashAttention-2 完全从头开始重写,使用 Nvidia 的 CUTLASS 3.x 及其核心库 CuTe 的原语(primitive)。
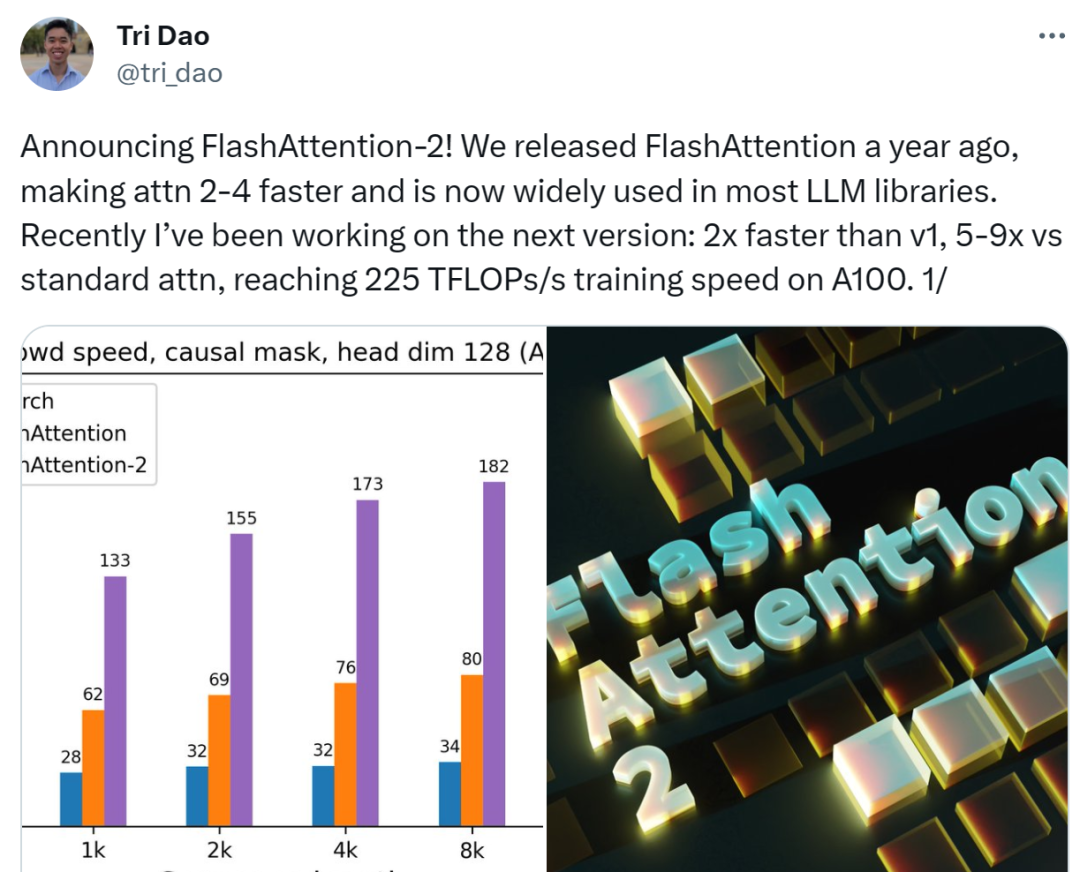
FlashAttention-2 的速度是 FlashAttention 的 2 倍,在 A100 GPU 上达到 230 TFLOPs/s。在端到端训练 GPT 类语言模型时,FlashAttention-2 可让训练速度高达 225 TFLOPs/s(模型 FLOP 利用率为 72%)。
FlashAttention-2 将加速现有模型的训练、微调和推理。这意味着我们可以用相同成本训练 2 倍上下文长度的语言模型。这将有助于语言模型理解长篇书籍和报告、高分辨率图像、音频和视频。

项目地址:https://github.com/Dao-AILab/flash-attention
技术报告:https://tridao.me/publications/flash2/flash2.pdf
FlashAttention 是什么?
FlashAttention 是一种重新排序注意力计算的算法,它利用平铺、重计算等经典技术来显著提升计算速度,并将序列长度中的内存使用实现从二次到线性减少。其中平铺意味着将输入块从 HBM(GPU 内存)加载到 SRAM(快速缓存),并对该块执行注意力操作,更新 HBM 中的输出。
此外通过不将大型中间注意力矩阵写入 HBM,内存读写量减少,带来了 2-4 倍的时钟时间加速。
下图为 FlashAttention 的前向传递图:通过平铺和 softmax 重新缩放,研究者按块进行操作,避免从 HBM 中读取 / 写入,同时获得正确的输出,无需近似操作。
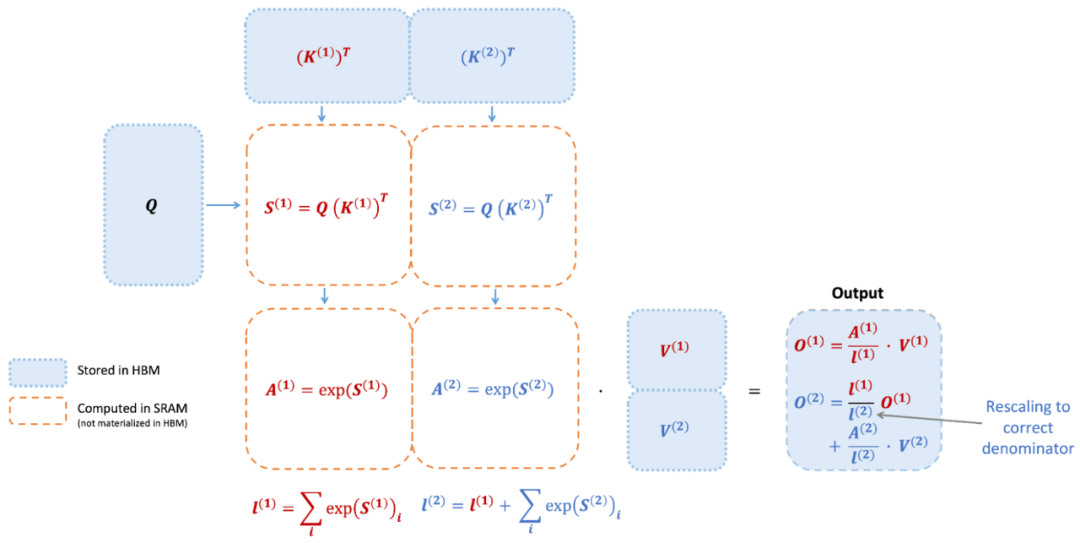
然而,FlashAttention 仍然存在一些低效率问题,原因在于不同线程块之间的工作分区不理想以及 GPU 上的 warp。这些导致低占用率或不必要的共享内存读写。
FlashAttention-2
更好的算法、并行化和工作分区
更少的非矩阵乘法 Flops
研究者调整了 FlashAttention 的算法,从而减少了非矩阵乘法(non-matmul)的 Flops 数量。这点很重要,因为现代 GPU 具有专门的计算单元(例如 Nvidia GPU 上的张量核心),使得矩阵乘法速度更快。
举例而言,A100 GPU 的 FP16/BF16 矩阵乘法的最大理论吞吐量为 312 TFLOPs/s,但非矩阵乘法 FP32 的理论吞吐量仅为 19.5 TFLOPs/s。
换一种思考方式,每个非矩阵乘法 FLOP 比矩阵乘法 FLOP 的代价高 16 倍。为了保持高吞吐量,研究者希望在矩阵乘法 FLOP 上花费尽可能多的时间。因此他们重写了 FlashAttention 中使用的在线 softmax 技巧,以减少重新缩放操作、边界检查和因果掩码操作的数量,而无需更改输出。
更好的并行化
FlashAttention v1 在批大小和头(head)数量上进行并行化。研究者使用 1 个线程块来处理一个注意力头,总共有(批大小 * 头数量)个线程块。每个线程块都计划在流式多处理器(SM)上运行,例如 A100 GPU 上有 108 个这样的 SM。当这个数字非常大(如 >= 80)时,这种调度是有效的,这时可以高效地使用 GPU 上几乎所有计算资源。
在长序列的情况下(通常意味着小批量或少量头),为了更好地利用 GPU 上的多处理器,现在研究者在序列长度维数上额外地进行并行化,使该机制显著加速。
更好的工作分区
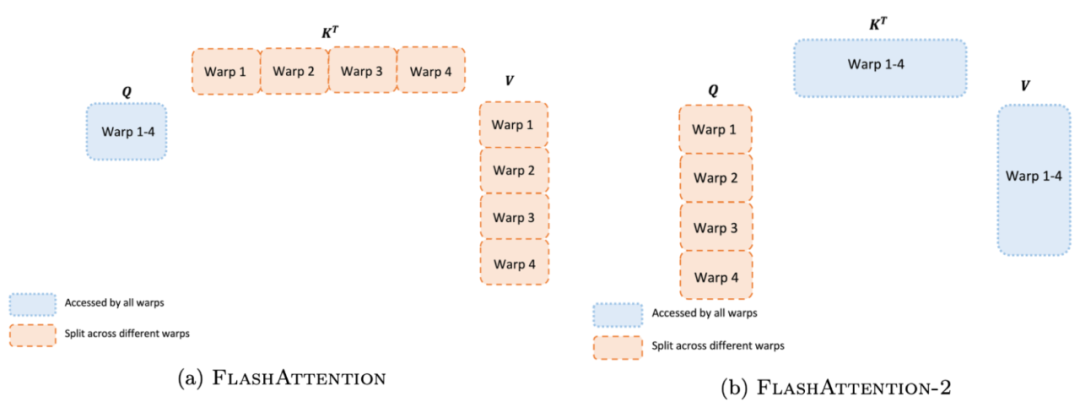
即使在每个线程块内,研究者也必须决定如何在不同的 warp 之间划分工作(一组 32 个线程一起工作)。通常情况下,每个线程块使用 4 或 8 个 warp,分区方案如下图所述。
研究者改进了 FlashAttention-2 中的这种分区,减少不同 warp 之间的同步和通信量,进而减少共享内存读写。
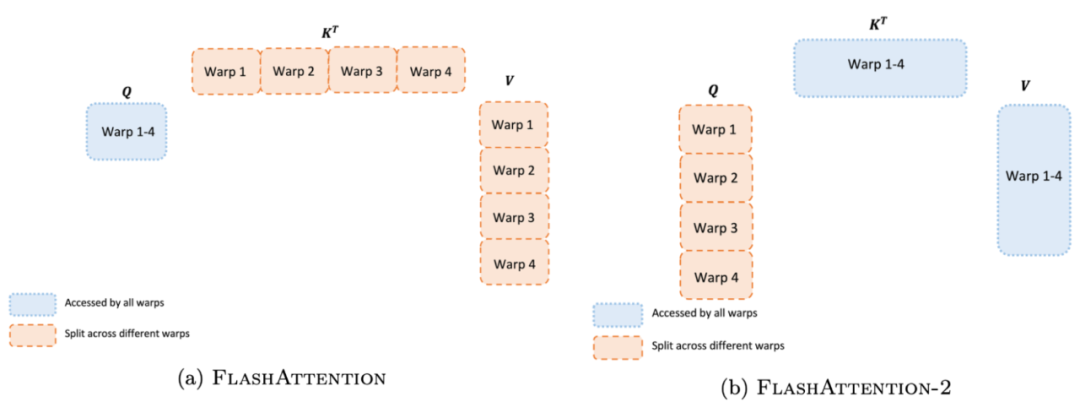
对于每个块,FlashAttention 将 K 和 V 分割到 4 个 warp 上,同时保持 Q 可被所有 warp 访问。这被称为「sliced-K」方案。不过,这种方案是低效的,原因在于所有 warp 都需要将它们的中间结果写入共享内存,并同步,然后将中间结果相加。这些共享内存读写会减慢 FlashAttention 中的前向传递速度。
在 FlashAttention-2 中,研究者将 Q 分割在 4 个 warp 上,同时保持 K 和 V 可被所有的 warp 访问。每个 warp 执行矩阵乘法以获得 Q K^T 的切片,然后只需与 V 的共享切片相乘就能获得相应的输出切片。warp 之间不需要通信。共享内存读写的减少也可以提升速度。
新特性:头维数高达 256、多查询注意力
我们知道,FlashAttention 仅支持最高 128 的头维数,这适用于大多数模型,但有一些模型被遗漏了。
因此,FlashAttention-2 支持了高达 256 的头维数,这意味着 GPT-J、CodeGen 和 CodeGen2、StableDiffusion 1.x 等模型可以使用 FlashAttention-2 来获得加速和节省内存。
此外,FlashAttention-2 还支持了多查询注意力(multi-query attention, MQA)以及分组查询注意力(grouped-query attention, GQA)。它们是注意力的变体,其中多个查询头关注相同的键和值头,以减少推理过程中 KV 缓存的大小,并可以显著提高推理吞吐量。
注意力基准结果
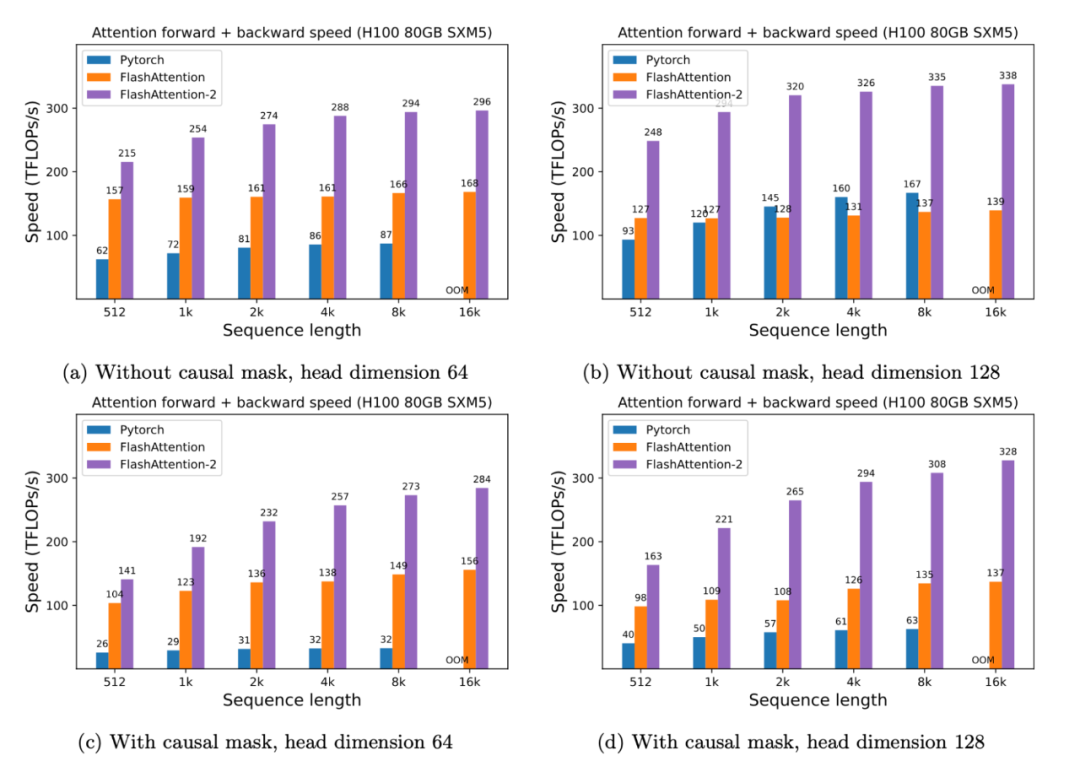
研究者在 A100 80GB SXM4 GPU 上,测量不同设置(无 / 有因果掩码、头维数 64 或 128)下不同注意力方法的运行时。
结果发现, FlashAttention-2 的速度是 FlashAttention(以及 xformers 库和 Triton 中的其他实现)的 2 倍。与 PyTorch 中的标准注意力实现相比,FlashAttention-2 的速度最高是它们的 9 倍。
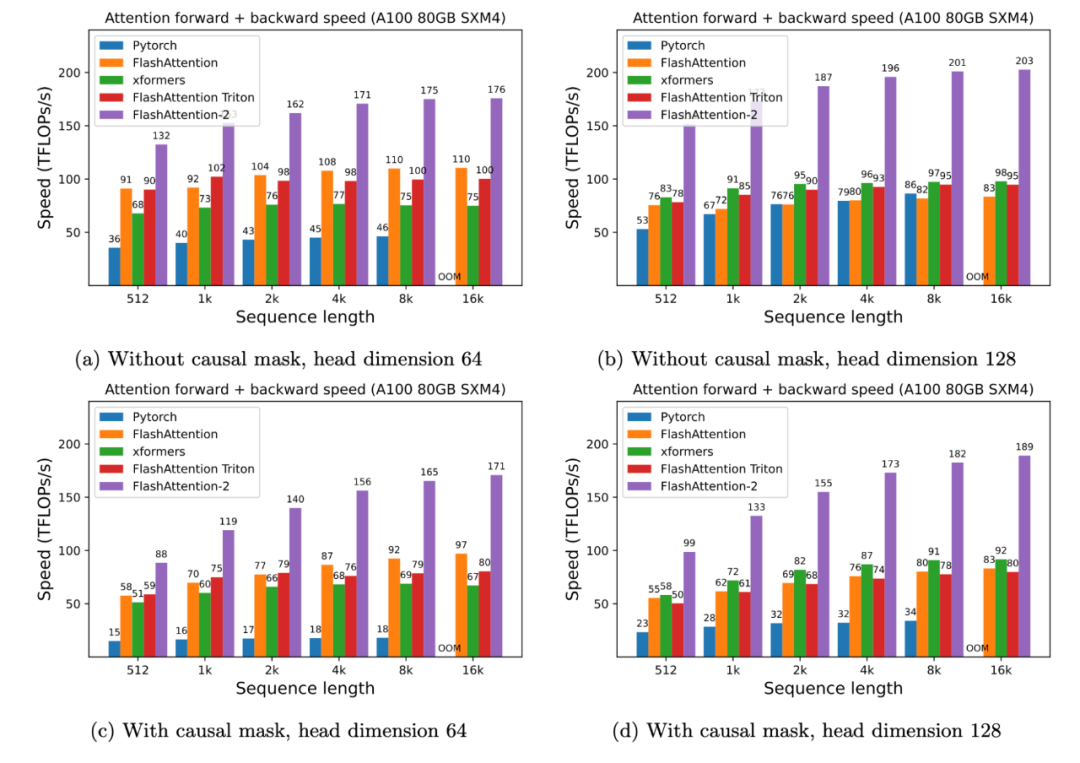
此外只需要在 H100 GPU 上 运行相同的实现(不使用特殊指令来利用 TMA 和第四代 Tensor Core 等新硬件功能),研究者最高获得了 335 TFLOPs/s。
当用于端到端 GPT 类模型训练时,FlashAttention-2 有助于在 A100 GPU 上实现最高 225 TFLOPs/s(模型 FLOPs 利用率为 72%)。与优化良好的 FlashAttention 模型相比,端到端实现 1.3 倍加速。
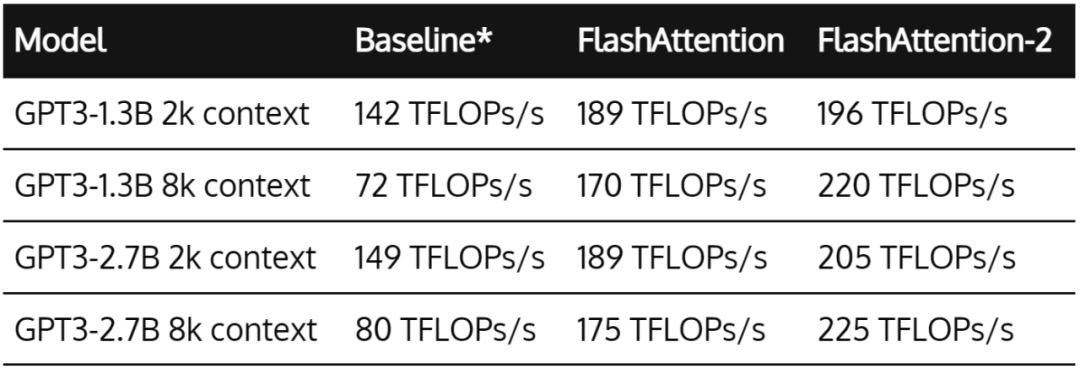
这里的基线是不使用 FlashAttention 的 Megatron-LM,它现在也可以选择使用 FlashAttention 了。不久的将来,FlashAttention-2 也将集成到 Megatron-LM 中。
研究团队表示:下一步将针对 H100 GPU 优化 FlashAttention-2,以使用新的硬件功能。





.jpg)