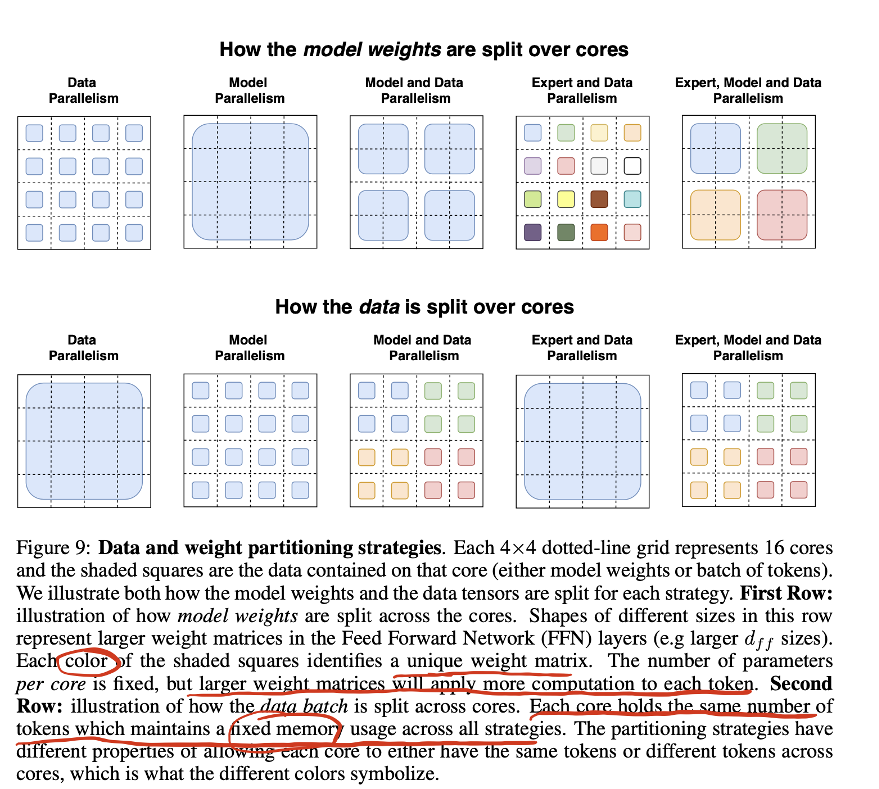
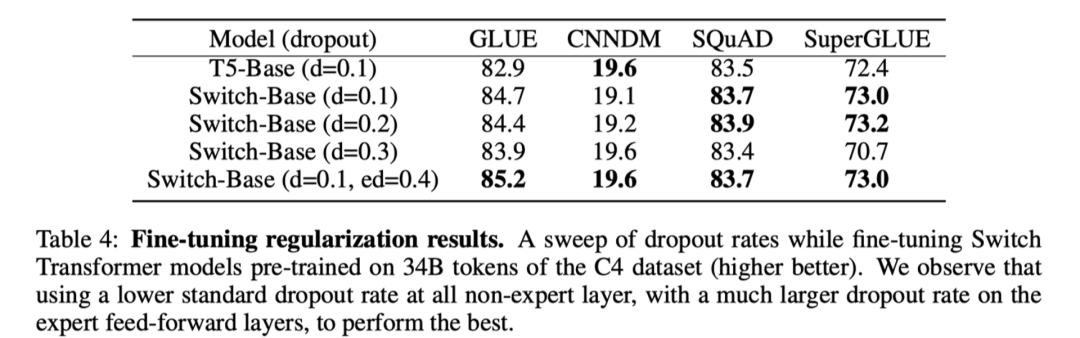
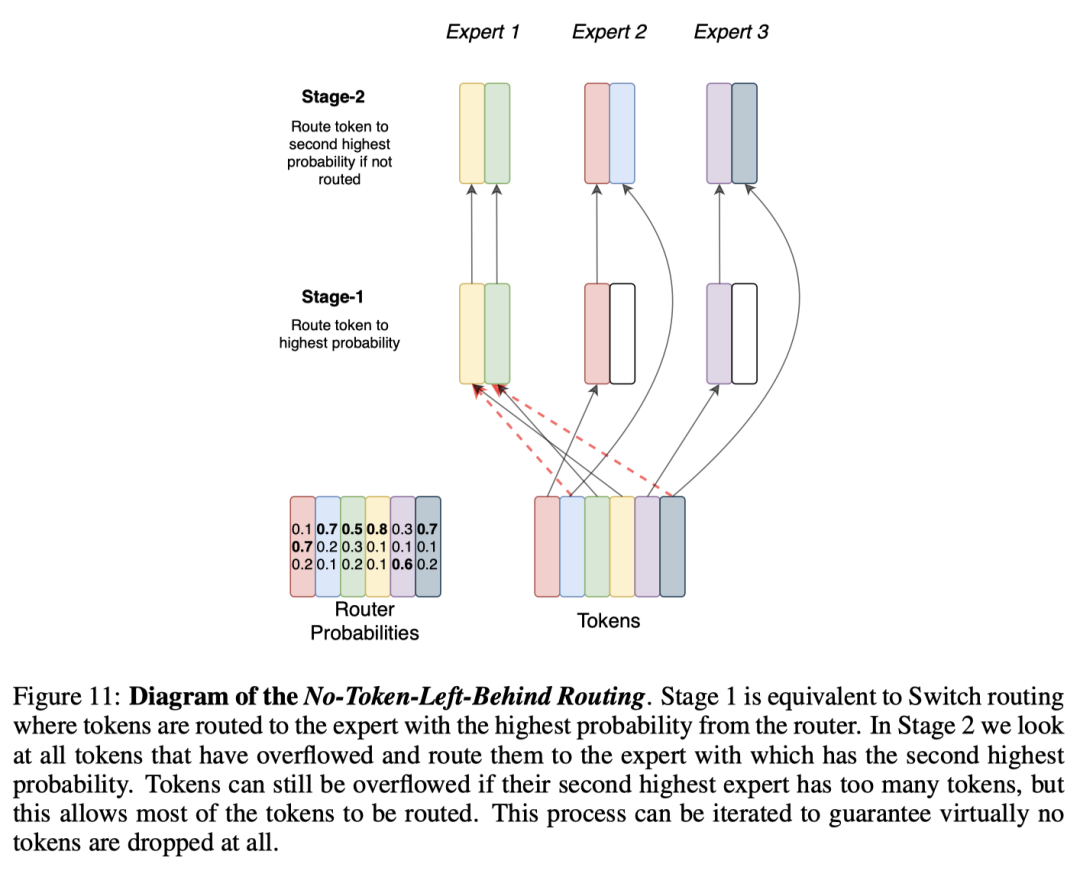
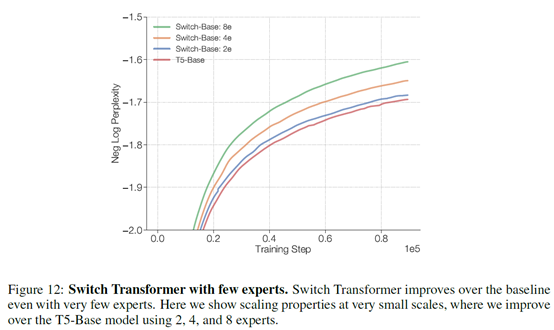
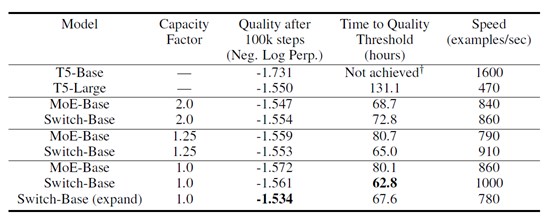
-
News Message
Switch Transformer: Google 语言模型
- by wittx 2023-02-02
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1120

Best Last Month

Information industry by wittx
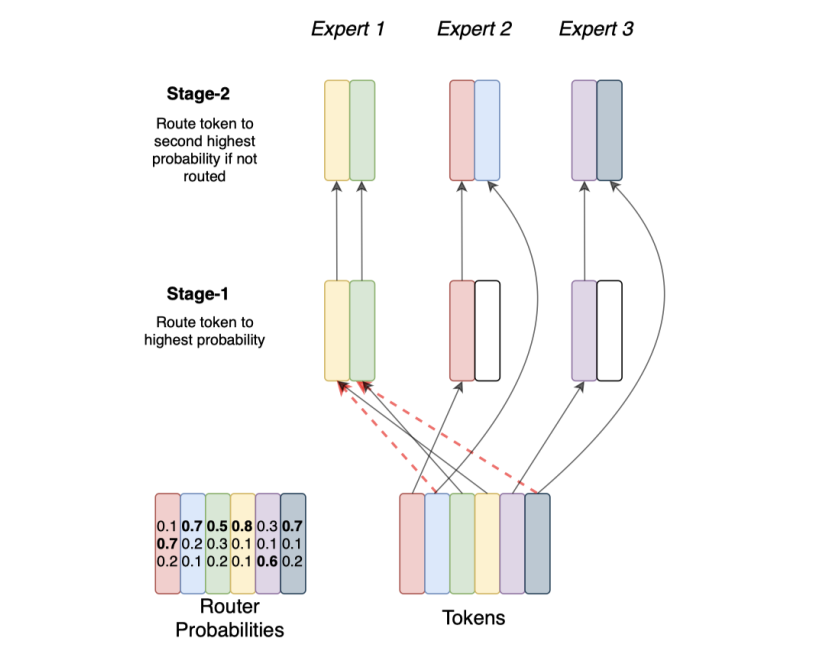
Information industry by wittx
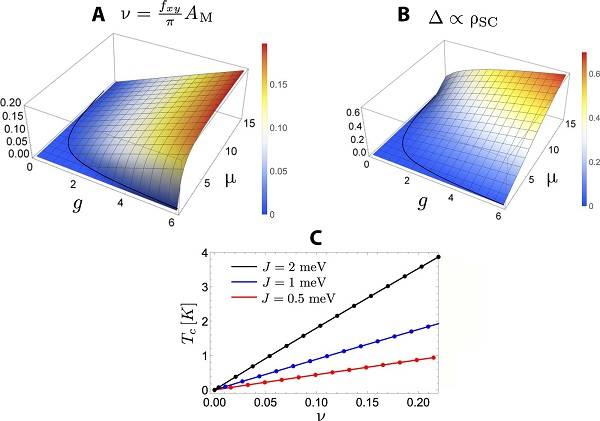
Information industry by wittx

Information industry by wittx
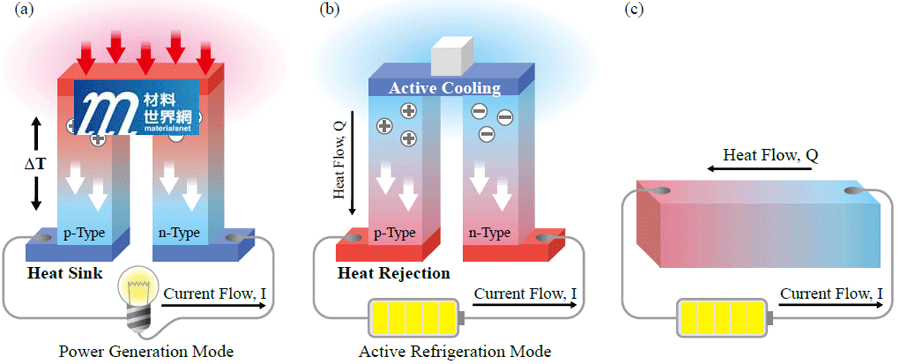
Information industry by wittx

Information industry by wittx

Information industry by wittx
Information industry by wittx
.jpg)
Computer software and hardware by wittx
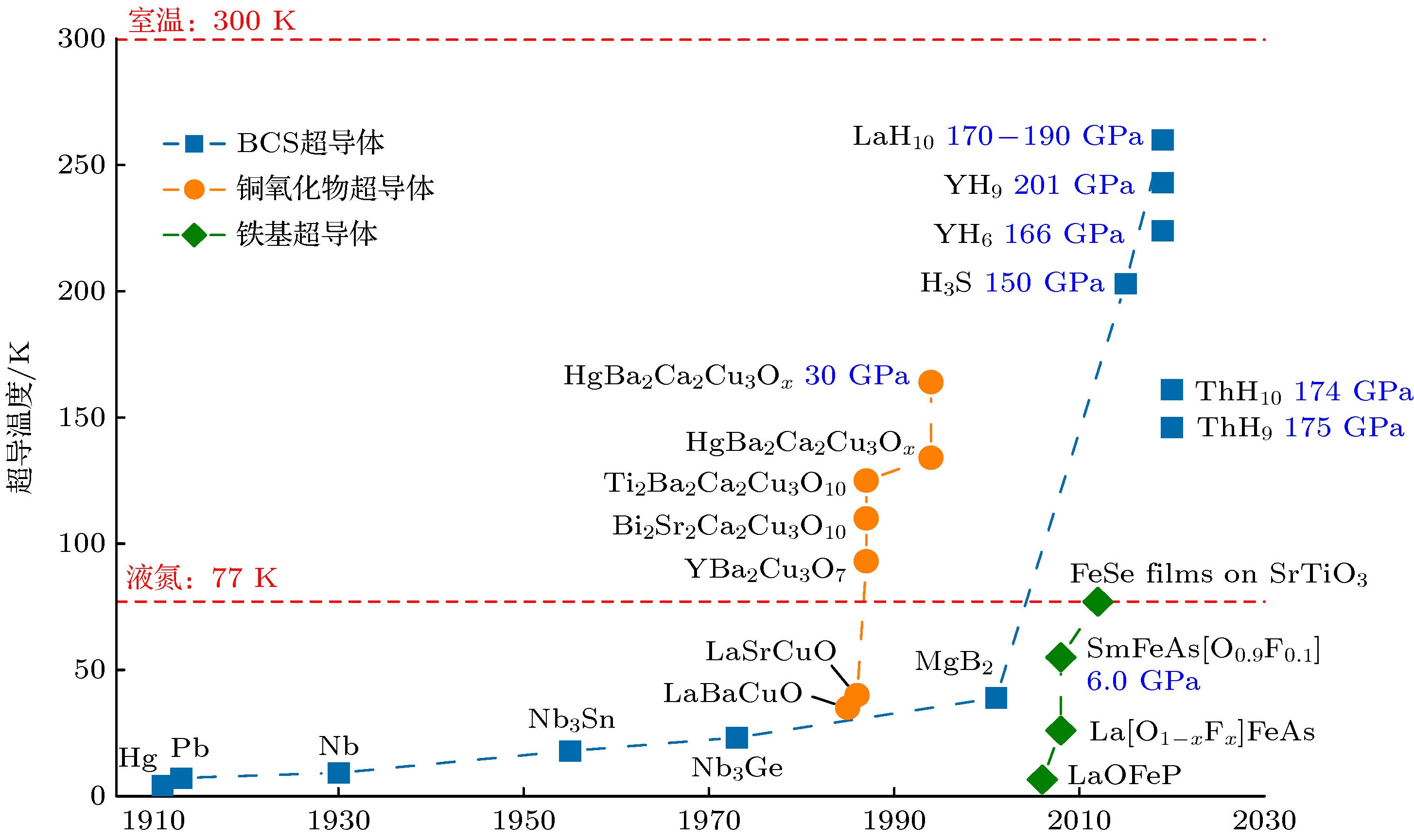
Information industry by wittxSuperconductor Pb10-xCux(PO4)6O showing levitation at room temperature and atmospheric pressure